linux下的二进制文件操作
二进制文件显示:
hexdump
命令语法:
hexdump: [-bcCdovx] [-e fmt] [-f fmt_file] [-n length] [-s skip] [file ...]
命令参数:
此命令参数是Red Hat Enterprise Linux Server release 5.7下hexdump命令参数,不同版本Linux的hexdump命令参数有可能不同。
| 参数 | 长参数 | 描叙 |
| -b | 每个字节显示为8进制。一行共16个字节,一行开始以十六进制显示偏移值 | |
| -c | 每个字节显示为ASCII字符 | |
| -C | 每个字节显示为16进制和相应的ASCII字符 | |
| -d | 两个字节显示为10进制 | |
| -e | 格式化输出 | |
| -f | Specify a file that contains one or more newline separated format strings. Empty lines and lines whose first non-blank character is a hash mark (#) are ignored. | |
| -n | 只格式前n个长度的字符 | |
| -o | 两个字节显示为8进制 | |
| -s | 从偏移量开始输出 | |
| -v | The -v option causes hexdump to display all input data. Without the -v option, any number of groups of output lines, which would be identical to the immediately preceding group of output lines | |
| -x | 双字节十六进制显示 |
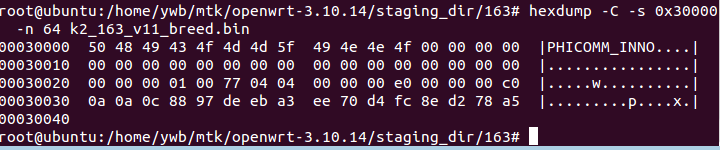
比如如下命令查看k2_163_v11_breed.bin文件从0x30000地址开始的64个字节内容:
# hexdump -C -s 0x30000 -n 64 k2_163_v11_breed.bin
dd:用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。
参数注释:
if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file >
of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >
ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes:同时设置读入/输出的块大小为bytes个字节。
cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。
count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
conv=conversion:用指定的参数转换文件。
ascii:转换ebcdic为ascii
ebcdic:转换ascii为ebcdic
ibm:转换ascii为alternate ebcdic
block:把每一行转换为长度为cbs,不足部分用空格填充
unblock:使每一行的长度都为cbs,不足部分用空格填充
lcase:把大写字符转换为小写字符
ucase:把小写字符转换为大写字符
swab:交换输入的每对字节
noerror:出错时不停止
notrunc:不截短输出文件
sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
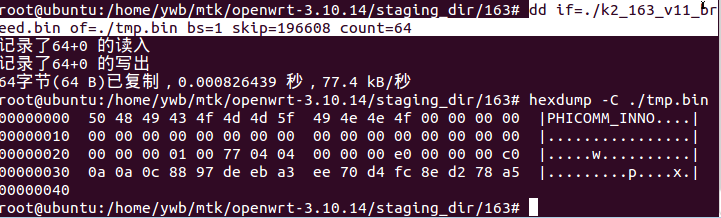
比如拷贝一个文件从偏移量0x30000(196608)开始的64个字节:
#dd if=./k2_163_v11_breed.bin of=./tmp.bin bs=1 skip=196608 count=64
sed是流编辑器,流既可以是字符流也可以是二进制流,可以针对文本字符或二进制字符进行修改替换,可以直接修改二进制文件。
$ sed 's/\x0D\x4D\x53\x48/\x0D\x0A\x4D\x53\x48/g' binfile > new_binfile





发表评论